You’d think chess is a cheap hobby. And, for the most part, you’d be right. Playing online is free, and physical pieces and boards are about the price of your Netflix subscription. But I, I confess, have not been learning chess the cheap way. I am a chess whale.
My addiction is every chess amateur’s favourite topic - openings. The first five to twenty five moves, depending on who you ask. I’ve played many different openings many different ways. I have freestyled, innocently mating my opponent half as often as I mated myself. And I have memorised, splurging through five Chessable ‘Lifetime’ repertoires that remain incomplete (for a Lifetime?).
The truth is, my openings still suck. As, I’m sure, do yours. But it’s not our fault. It is, I concluded conveniently, our repertoires’ fault. They are not built for humans. OpeningBuilder is my attempt to fix this.
Who’s winning here?
Why your opening repertoire sucks:
You are learning moves you will never play.
Most opening repertoires are either exhaustive or insufficient.
There are the Chessable courses or books with thousands of lines averaging 15 moves deep, answering engine responses to engine novelties that no human has ever even played and maybe never will. Fine, if you are a Grandmaster who wants to dedicate their life to learning a Chessable course. Not fine if you want to play chess.
And there are scant Lichess studies or Chessable courses designed for ‘club players’. Somehow they’re still too long, but only cover cheap lines that end in checkmate or queen traps. You mostly end up out of book on move 3. Also no good.
Almost all repertoires are organised according to the author’s whim. Never mind what lines you’re actually likely to get in your games.
The reality is that chess is a game with a lot of possibilities, and real players play weird moves. Even the most common main lines are rare. If you calculate the probabilities (I’ll show you how later), somewhere around move 5-10 your odds of being in a common ‘mainline’ round to about 0%, even if you play perfect mainline theory every time. Memorising 20 moves deep is as useful as memorising the numbers on winning lottery tickets.
A practical repertoire teaches you only what’s worth you remembering. No more, no less.
You are not a chess engine.
Most opening repertoires treat the engine’s evaluation as the ‘truth’, seeking out risk free routes to a small engine evaluated advantage in as many lines as possible.
This makes sense: a 100 centipawn advantage (something like having 1 pawn extra) is enough for a strong engine to win most of the time. 100 abstract centipawns are, however, for everyone but the most elite human players, practically useless.
For humans, some types of positions are easier to play than others, and some types of engine evaluated advantages are impractical to convert, especially for weaker players. Check your last game for how often you or your opponent dropped 100 centipawns in a single move according to the engine. Chances are it happened multiple times.
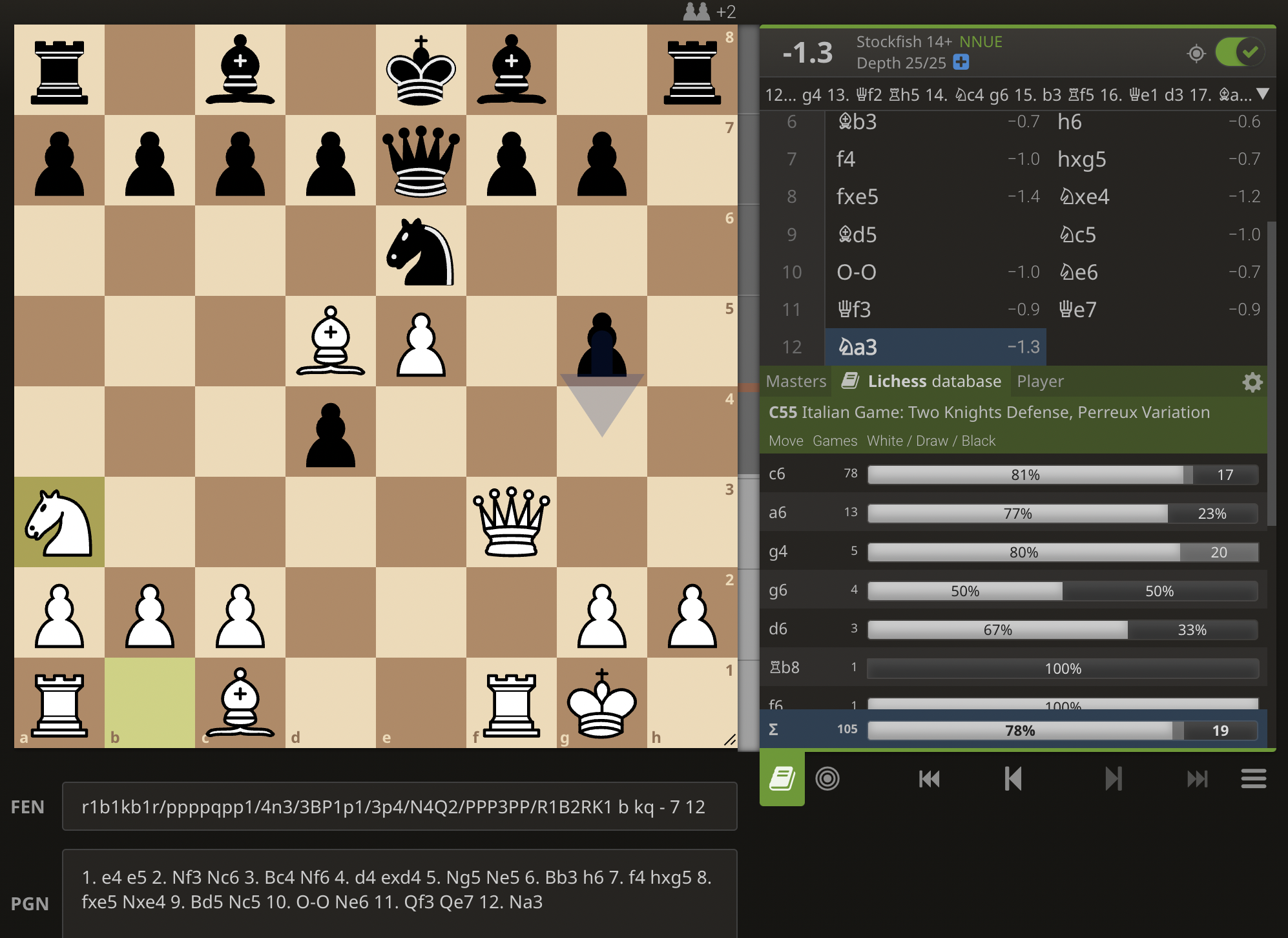
Even in the recent Candidates tournament, where games take several hours, the world’s strongest players could not reliably win from small engine evaluated advantages. Outside elite level, many positions which are certain wins for an engine are positions humans are statistically highly likely to lose! Check the position in the photo above.
A practical repertoire gives you positions you can actually win, not positions you should win.
What your opening repertoire should be:
Only the moves you actually need to know.
Using data on move play rates, we can build comprehensive repertoires with 10x less memorisation.
We now have access to the Lichess database: hundreds of millions of games by players of various ratings. We know which moves players play, in which time controls, at which level.
And with this data, we don’t need to create repertoires to a naive depth of, say, 10 or 20 moves, or whenever the course creator decides the line stops. We can create repertoires to a depth which reflects the probability that you will encounter a given move in your games.
For example:
If you play 1.e4, in Lichess Blitz across all ratings, your opponent will respond with …e5 about 31.5% of the time. If you then play 2.Nf3, your opponent will play the Petrov …Nf6 11.7% of the time. So, assuming you play e4 and Nf3 all the time, you’ll need a response to …Nf6 in around 3.7% of your games. If you then play 3. Nxe5, your opponent will play …d6 43.7% of the time, so you’ll need a response to that in around 1.6% of your games. This is the cumulative probability of the line.
Repertoires should be built according to the probability of you actually needing to play the move. For example, a line could stop after the move is likely to appear in less than 1 in 1000 games.
This allows repertoires to differentiate between moves you need to memorise, and moves you don’t. And doing this alone makes a massive difference.
A complete White or Black repertoire, with a response to every move that occurs at least once every thousand games, is shockingly small. Typically, it’s around 250-350 lines at an average of 6 moves deep, with only one or two new moves per line.
The ‘Keep it Simple 1.d4’ repertoire on Chessable is 1009 lines, averaging 13.7 moves deep. That’s almost 10x bigger than it needs to be for it to cover the moves you’ll see once or more every 1000 games. What is simple about that repertoire?
A practical repertoire is compact and easy to learn, based on play rates.
Moves that actually help you win.
Using data on win rates, we can create courses that are easy to learn, play, and win with.
The Lichess database doesn’t just tell us play rates. It tells us win rates. We know which moves have what probability of leading to a win, in which time control, at which level.
Even simple win rates are surprisingly powerful.
Win rates tell us how easy to play the position is. If an engine evaluates the position as a draw, but Black wins 75% of the time over 100 games, who has the better position? Easy to play positions are valuable: if we forget our lines, we want positions where it’s easy for us to find the winning moves and hard for our opponents.
Win rates tell us which engine advantages are human advantages. Would you rather play a move which is winning by 600 centipawns according to the engine but has a win rate of 10% because you need to find an unintuitive plan to win, or a move which is winning by 100 centipawns but has a win rate of 90% because your opponent needs to find an unintuitive plan to hold?
Win rates tell us the value of a rare move. We want to be in book while our opponents are out of book, but this is risky: rare moves are often rare for a reason. Win rates help you figure out if a move creates more problems for your opponent than it does for you, especially when it’s not the engine’s top move. Except at the highest level, you don’t want total novelties, you want sound rare moves backed by good win rates.
If we take a simple algorithm like: ‘always pick the move that has the highest win rate in the Lichess database’, the results are surprisingly powerful. The lines are easy to learn, play, and usually end up in a win. Left unsupervised, picking by win rate often finds lines with dubious gambits humans find hard to refute. With some simple engine supervision like ‘never pick moves that leave you more than 100 centipawns down’, the algorithm finds lines you’ll pay good money for on Chessable.
A practical repertoire is easy play and win with, based on win rates.
You can now automatically make a practical opening repertoire for any opening
So, I built OpeningBuilder - www.openingbuilder.com. OpeningBuilder is a free, open source program that will generate you an opening repertoire for any openings you want to play.
You can input any PGN starting point like ‘1.e4’, or ‘1.d4 e5’, or even hundreds of PGNs at the same time. OpeningBuilder will generate an opening repertoire by selecting the winningest moves in every position that you’re likely to get.
There are some powerful customisations:
You can decide the repertoire depth as a cumulative probability based on play rates. So for example, a depth of 0.01 would give you a repertoire where the lines will end once the next move has less than 1% probability of occurring.
You can decide what time controls and rating ranges you would like play rates and win rates to come from. You can build a blitz specific or 2000 specific repertoire. Or use all the data available.
You can control the soundness of the repertoire. If you never want to be more than 50 centipawns down, or sacrifice more than 50 centipawns to play a move with a higher win rate, you can do that.
You can finish lines with the engine. If there isn’t enough data to reliably pick between moves, you can opt to have lines ‘finished’ by the engine.
And a bunch more.
The output is a PGN file (or multiple files if you started with multiple PGNs) which you can upload into Chessable, Lichess, Chesstempo, ChessBook, or any other learning software to memorise. The lines are concise and strong, backed by data and engines.
It’s super fun to play with, so give it a try. You can make a short (5% depth) e4 repertoire for White, or an e4 e5 repertoire for Black in about 15 seconds.
FAQ
Can it do any opening? Do you have an example?
Absolutely, as long as it’s been played before. It can generate you a grinding Reti course, or a razor sharp Latvian, depending on your settings.
I created a Blitz repertoire with almost no concern for soundness, entirely using gambits you’d struggle to find a course for anywhere. It’s amazing fun for online blitz, with wild (often winning) games. I created a slightly more sound Blitz repertoire for white which might appease pickier players. I created a sound ‘tournament’ repertoire which is complete for White and Black in about 600 lines total, averaging 6 moves deep. The critical responses are covered and where it matters the depth goes into the double digits. I’m not linking that ;)
Does it come up with interesting stuff? How do the lines compare to paid courses?
You bet. There are a bunch of fascinating discoveries you can make by playing with the settings and starting points. Who knew about the Portsmouth Gambit (1. e4 c5 2. Nf3 Nc6 3. b4), a chaotic version of the Wing gambit which scores well even at high level play?
That said, if you dial in stricter soundness settings on the engine side, you’ll get much more solid approaches similar to those recommended by Masters in Chessable courses. Honestly, some popular courses (which I shall not name) are more or less just following win rate recommendations with strict soundness limits.
Can you make this into a web application?
It now is! OpeningBuilder.com
Is the algorithm just climbing win rates?
More or less. We allow you to tweak things though, so you can bias the algorithm to pick moves with more data (or less), only pick moves with minimum play rates (by percentage or absolute), only pick moves within certain engine criteria, rating ranges, or time controls etc.
There are probably more sophisticated win rate functions that could be incorporated. Right now it just uses a confidence interval to account for variances in win rate sample size for each move and prioritise moves with larger sample sizes.
Why does the code look like it was written by someone who can’t code?
Because I didn’t know how to code until I made it.
Did you write this from scratch?
Nope. I started with the Chess Trap Scorer which was super helpful to get going.
Is this useful for very strong players in classical chess?
No. If you’re trying to prepare for your opponents’ novelties, this won’t help.
How long does it take to make a repertoire?
If you don’t use an engine, it can take seconds or minutes to build a full repertoire. If you want to use the engine features, it depends on how good your computer is and how deep you run the analysis. For deep (eg 35 for) analysis you might have to leave it for a few hours.
Does this miss lines where you have to walk a narrow but sure path to victory that most players don’t know about?
Sometimes. For most players I don’t think these lines are practical, though.
Does this miss lines that are ‘busted’ on move 24 by a novelty?
Sometimes, especially if you don’t use engine assistance.
Does this help learn middlegame plans?
No, but middlegame plans are probably not worth memorising move for move as part of a ‘repertoire’ anyway. Just check model games, watch videos, etc.
Does this annotate the lines?
No. The only annotations are play rates and win rates.
Are there other obvious flaws with the statistical approach?
Yes. The most obvious improvement would be something which looks deeper into the tree so that we calculate the win rate assuming we play only the lines we play (right now the win rate includes lines we don’t intend to play). That said I couldn’t figure out how to do this without hitting API limits, it may result in some hard to play or unintuitive lines or bad data, or just be slow. Would love to see someone try.
Another problem is that sometimes the deeper lines that are the highest win rate are less sound than the initial position, so strict engine settings will make the some win rates less accurate as some later moves are not playable. So it’s possible to pick a move with (say) a 60% win rate but find that the deeper moves that win rate was generated by are not actually within your soundness threshold, and alternative moves are a lower win rate.
How does this handle transpositions?
Quite well. It’ll always pick the same move in a given position with the same settings, unless the stats have changed meaningfully in the time the program takes to run, which is unlikely. On the other hand, it might lean away from transposing to a known line if a winninger alternative is found.
Why did you not do XYZ when you open sourced this?
Because I’ve not done this before.
Can I contact you about a bug/feature/something else?
Yes.